
¿Cómo funcionan los árboles de decisión en machine learning?

Los árboles de decisión son un tipo de aprendizaje automático supervisado destinado a realizar predicciones en función de un conjunto de preguntas a las que el sistema ha de responder y realizar una predicción.
¿Cómo funcionan los árboles de decisión?
Podemos asemejar el funcionamiento de un árbol de decisión al de la simple mecánica del juego infantil “veo, veo”.
Imagina que queremos que unn ordenador aprenda a distinguir entre diferentes tipos de frutas, como manzanas y naranjas. El árbol de decisión empezaría con una pregunta, como “¿Es la fruta redonda?” Si la respuesta es sí, entonces la computadora podría preguntar “¿Es la fruta roja?” Si la respuesta es sí de nuevo, podría decidir que la fruta es una manzana. Si la respuesta es no, podría ser una naranja. Si la fruta no es redonda, el sistema formularía otra pregunta a raíz de otra característica, como “¿Es la fruta de color naranja?”
El árbol de decisión sigue haciendo preguntas y tomando decisiones basadas en las respuestas hasta que clasifica correctamente todas las frutas en grupos.
Nodos raíz y nodos de decisión
Así pues, un árbol de decisión es parecido a un árbol. A la base del árbol se le llama nodo raíz, a partir del cual nacen los nodos de decisión, que representan posibles preguntas por las que se quiere segmentar toda la muestra. La formulación de estas preguntas dependerá de las variables que hayamos identificado y que queramos utilizar para segmentar el conjunto de datos.
Divisiones y subnodos
A estos nodos de decisión les corresponden una, dos o más respuestas, llamadas divisiones o particiones. Cuantas más particiones o respuestas posibles tenga un nodo de decisión, más subnodos de decisión se crearán, y mayor será la complejidad del árbol.
A medida que avance al árbol y sus ramificaciones, el número de nodos de decisión se irán reduciendo y el conjunto de datos se irán clasificando en subconjuntos más homogéneos basándonos en ciertos criterios.
Hojas
El objetivo del árbol de decisión es que el sistema de inteligencia artificial vaya cribando poco a poco el conjunto de datos y los categorice con precisión y rigor. Así pues, el árbol de decisión termina en hojas, es decir, respuestas únicas sin particiones para todos los nodos de decisión.
Poda
A medida que va ramificándose el árbol en particiones, es necesario ir filtrando nodos para evitar que crezca en exceso con información que no nos es relevante para nuestros propósitos. Esta depuración del modelo de inteligencia artificial, también llamada en inglés “pruning”, se realiza durante el diseño del árbol de decisiones, así como después de completar todo el árbol. Es una forma de simplificar el modelo, hacerlo más útil y evitar que se sobreajuste a los datos del entrenamiento.
¿Para qué sirven los árboles de decisión?
Los árboles de decisión en el machine learning se emplean para:
Clasificación de datos
Con estos árboles podemos clasificar datos en diferentes categorías o clases. Por ejemplo, en medicina, se pueden utilizar para clasificar pacientes en diferentes grupos de riesgo según sus características médicas. En marketing, pueden ayudar a segmentar clientes en grupos basados en su comportamiento de compra.
Predicciones
Su aplicación más útil y extendida es la de hacer predicciones sobre valores numéricos. Por ejemplo, en finanzas, se utilizan predecir el precio futuro de las acciones en función de diferentes factores económicos. En meteorología, pueden predecir la temperatura o la cantidad de precipitación en función de variables como la presión atmosférica y la humedad. Los árboles de decisión son especialmente útiles cuando se desea comprender cómo las diferentes características afectan a la variable objetivo.
Detección de anomalías
Por ejemplo, en ciberseguridad, se pueden utilizar para identificar actividades sospechosas (patrones de uso irregular) en una red, como intentos de piratería o intrusiones. En la detección de fraudes financieros, los árboles de decisión detectan transacciones inusuales que podrían ser indicativas de actividad fraudulenta y a prevenirlos cuanto antes.
Ejemplo de árbol de decisión
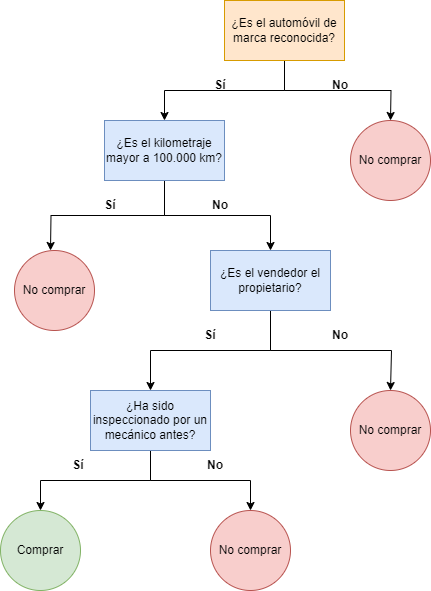
Te dejamos un ejemplo muy simple de árbol de decisión de tipo clasificatorio para que comprendas cómo funciona esta técnica. Si se desarrollara un sistema de inteligencia artificial más elaborado con un conjunto de datos grande proveniente de un concesionario, podríamos predecir si un potencial comprador acabaría comprando o no un coche de segunda mano.
El bloque amarillo es el nodo raíz. Los bloques azules son los nodos de decisión. Los círculos verdes y rojos representan las hojas, en las que se decide la decisión final según cada respuesta a cada nodo.
Ventajas y desventajas de los árboles de decisión
Los árboles de decisión en machine learning son una técnica muy útil y popular por las siguientes razones:
- No requieren mucho tiempo de preprocesado y limpieza de datos: A diferencia de algunos otros algoritmos de aprendizaje automático, los árboles de decisión pueden manejar datos con diferentes tipos de variables (categóricas y numéricas) sin necesidad de una preparación extensa. Trabajar con árboles de decisión es muy eficiente, ya que no se ha de perder mucho tiempo antes de elaborar uno.
- No importa si el dataset tiene lagunas: Los árboles de decisión pueden manejar conjuntos de datos incompletos, es decir, conjuntos de datos que tienen valores faltantes o lagunas.
- Es sencillo de explicar visualmente a otras personas: Los árboles de decisión son fáciles de entender y visualizar, incluso para personas que no tienen formación específica en el área. Puedes representar un árbol de decisión como un diagrama que muestra las decisiones tomadas en cada nodo y cómo se llega a una conclusión para facilitar que otras personas comprendan el modelo que estás entrenando.
Sin embargo, debemos ser conscientes de que los árboles de decisión tienen sus limitaciones y desventajas, como las siguientes:
- Inestabilidad: Los cambios en los datos o la presencia de ruido pueden hacer que la estructura del árbol varíe enormemente. En esencia, los árboles son sensibles a pequeñas variaciones en los datos de entrenamiento o a la presencia de ruido. Es decir, si los datos cambian un poco o si hay errores en los datos, la estructura del árbol resultante puede verse muy alterada, haciendo que la toma de decisiones sea menos rigurosa según las predicciones.
- Lleva más tiempo entrenar un modelo usando un árbol de decisión: Aunque los árboles de decisión son relativamente rápidos en la etapa de predicción, pueden llevar más tiempo entrenar el modelo, especialmente si el conjunto de datos es grande o si el árbol crece demasiado. Esto se debe a que el algoritmo necesita considerar todas las posibles divisiones y características para construir el árbol, lo que puede ser computacionalmente costoso.
- Sobreajuste (overfitting): Los árboles de decisión tienen una alta capacidad para adaptarse a los datos de entrenamiento, lo que conduce a una situación de overfitting. El sobreajuste ocurre cuando el modelo se ajusta demasiado a los datos de entrenamiento y captura el ruido o las características específicas de esos datos en lugar de aprender patrones generales que se puedan generalizar a nuevos datos. Así pues, cuando a un modelo sobreentrenado lo allimentamos con información de un conjunto de datos diferentes, ofrece muchas respuestas incorrectas y un rendimiento ínfimo.
Tipos de árboles de decisión
Diferenciamos los siguientes árboles de decisión según su enfoque:
De clasificación
Este tipo de árbol se utiliza cuando la variable objetivo es categórica, es decir, pertenece a un conjunto discreto de clases o categorías. El árbol de clasificación divide el conjunto de datos en función de las características para clasificar las instancias en diferentes categorías. Por ejemplo, puede clasificar correos electrónicos como spam o no spam, pacientes como enfermos o sanos, o clientes como compradores o no compradores.
De regresión
Un árbol de regresión se utiliza cuando la variable objetivo es numérica o continua, es decir, puede tomar cualquier valor dentro de un rango específico. El árbol de regresión divide el conjunto de datos en función de las características para predecir un valor numérico. Por ejemplo, puede predecir el precio de una casa en función de su tamaño, la cantidad de habitaciones, la ubicación, etc. o predecir la temperatura máxima diaria en función de variables meteorológicas como la humedad, la presión atmosférica y la velocidad del viento.
Artículos relacionados

Conoce la eficiencia de Pentaho en el BI y análisis de datos

El algoritmo de Shor: Revolucionando la factorización en la computación cuántica
El algoritmo de Shor es uno de los avances más importantes en la computación cuántica.
